Agile Analytics & Operational Intelligence for COVID-19
The global outbreak of SARS-CoV-2 (COVID-19) has been filled with uncertainty. Who is most at risk? Which symptoms are most common? What treatments are effective? Agile technical architectures and applications are needed to support the high volume and constantly evolving data created in healthcare.
The global outbreak of SARS-CoV-2 (COVID-19) has been filled with uncertainty. Who is most at risk? Which symptoms are most common? What treatments are effective? The incredibly varied presentation, from asymptomatic patients to significant mortality further complicates assessing the true scope of infection and drives further uncertainty in how to respond to and manage the pandemic. Rapid turnaround in research from China and other locations with some of the first cases have provided invaluable information to guide the next stage of research and treatment. However, as large-scale clinical trials are difficult to deploy rapidly, much of the next wave will rely on real-world data (RWD) and observational studies paired with basic and translational research to guide the response to and management of COVID-19.
Investigators are rapidly trying to research COVID-19 in a new paradigm of research: a rapidly spreading global pandemic with tools not available before. From rapid genomic sequencing to computational modeling to AI-based predictions, researchers can build data-driven models of how infection occurs and spreads, create diagnostic tests at unprecedented speed, model viral protein structure, identify possible therapeutic agents, and predict patient outcomes. Data is a key analyte for all of these studies and obtaining high-quality RWD will be critical to accelerate discovery.
The direct patient care response has also taken a data-driven approach at many healthcare organizations. The ability to harness clinical and operational data has the potential to guide real-time operational decisions. Similar to the unknowns of the virus, healthcare administrators and providers need to rapidly identify key indicators. How many people have been infected? How many beds remain available in the hospital and/or health system? What is available for intensive care capacity and how many ventilators are available? How many healthcare providers have been exposed or are undergoing testing, and how does this impact our readiness to respond to the rapidly increasing number of people testing positive with COVID-19?
To provide the data needed to generate evidence and information, infrastructure to support real-time data acquisition and agile analytics are a necessity. Technologies to support this can range from on-premise solutions to managed cloud-based services. Within our organization, we deployed a data science platform, based on open-source technology, to support these needs several years ago (McPadden, et al. 2019) which we have rapidly leveraged for agile analytics to support data-driven decision making in the current outbreak.
We acquire billions of data points per month with this platform, from electronic health record (EHR) data to continuous physiologic monitoring and ventilator data. This is built on top of a large data warehousing strategy within the organization to support operational, clinical, and research analytics. This platform is now being expanded to include scalable end-user analytical tools, the integration of genomic data, and self-service tools for data sandboxing. By using this existing infrastructure and some of the new tools offered by the expansion, we have been able to rapidly deploy operational and clinical quality tools to assess our early response to the COVID-19 pandemic.
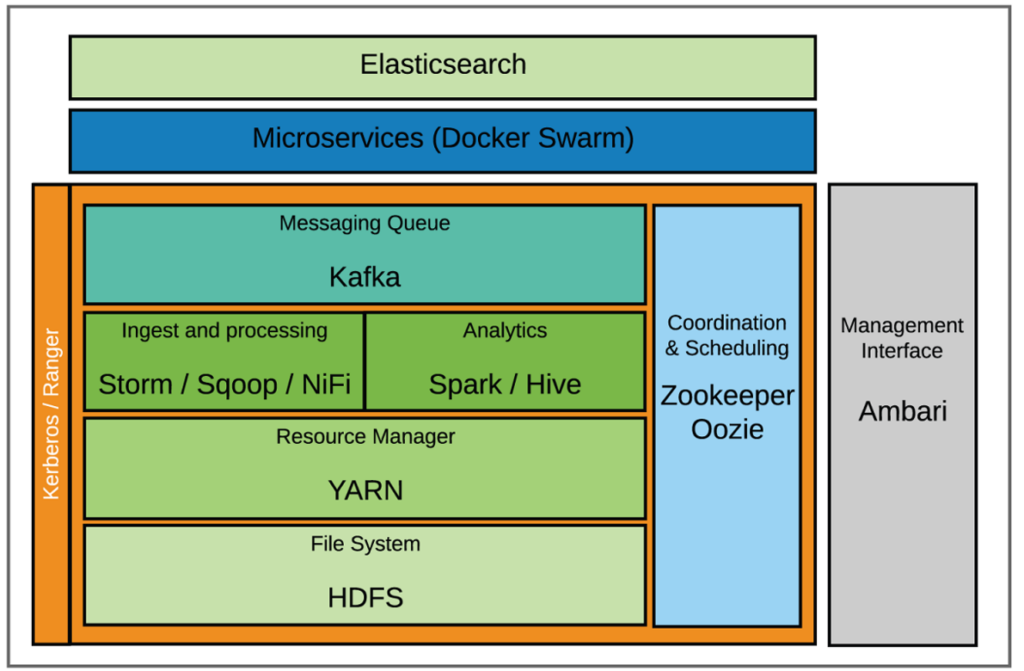
We have operationalized our infrastructure to guide data analytics and software development best practices through all steps of the analytical workflow (data preparation through report delivery). This includes an integrated environment for data acquisition, storage, and compute with common data standards and scalable compute that data-driven applications and analytic tools can deployed on.
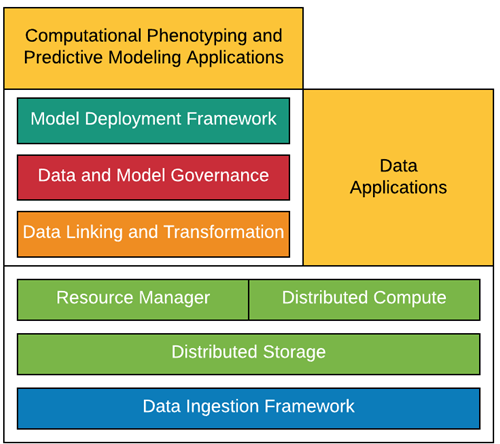
To guarantee high-quality data, we have developed a team of experienced clinical informaticists, data science engineers, analysts, data architects, and software developers that span our academic healthcare center, including the school of medicine and health system. This combination of team and technology allowed us to quickly deploy data-driven tools to guide our organizational response to COVID-19 and develop the data assets that will be needed to drive discovery.
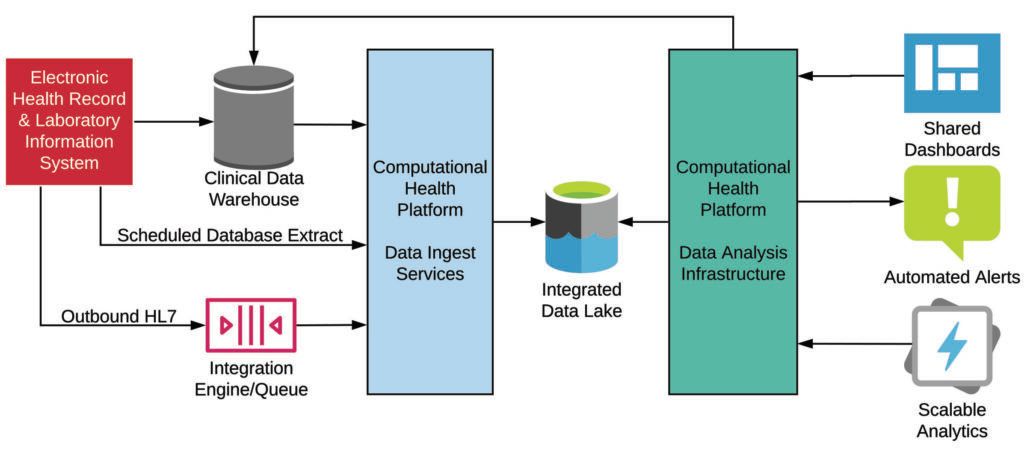
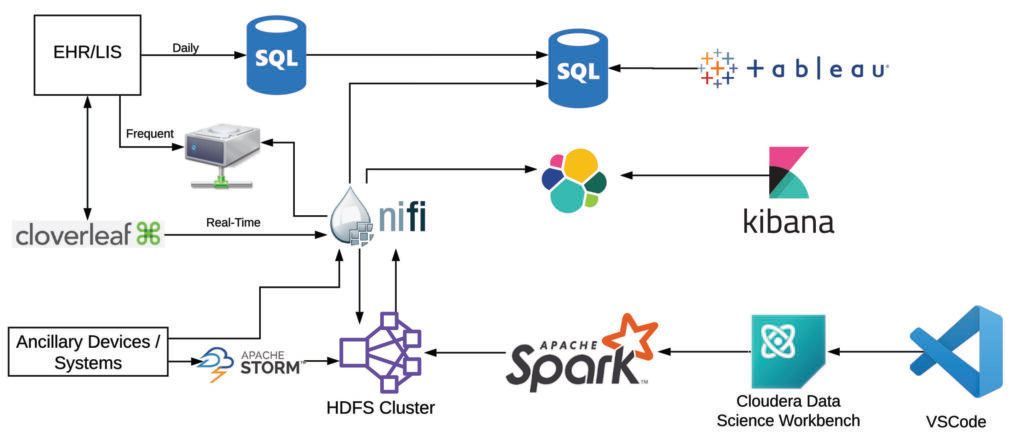
We use a diverse set of data sources and tools to support these complex workflows and the needs of stakeholders throughout the organization. Gold-standard data are acquired from our clinical data warehouse, which is updated nightly from our EHR. Additional data are obtained in more frequent batches (eg, every 15 minutes, every hour) from data extracts from the clinical database. Real-time data are also acquired from various healthcare IT systems, including select EHR data elements, through our data integration engine. Other real-time data sources include our physiologic monitors and ventilators, which are streamed directly from vendor middleware or integration services. These data are ingested with various tools depending on the source. The high-volume physiologic monitors are transformed using Storm, intermediate-volume real-time data with NiFi, and batch/data warehouse data with sqoop. These data are transformed into various standards within HDFS (primarily a JSON adapted version of HL7 for raw data and OMOP with some extensions to support real-time and clinical/operational use).
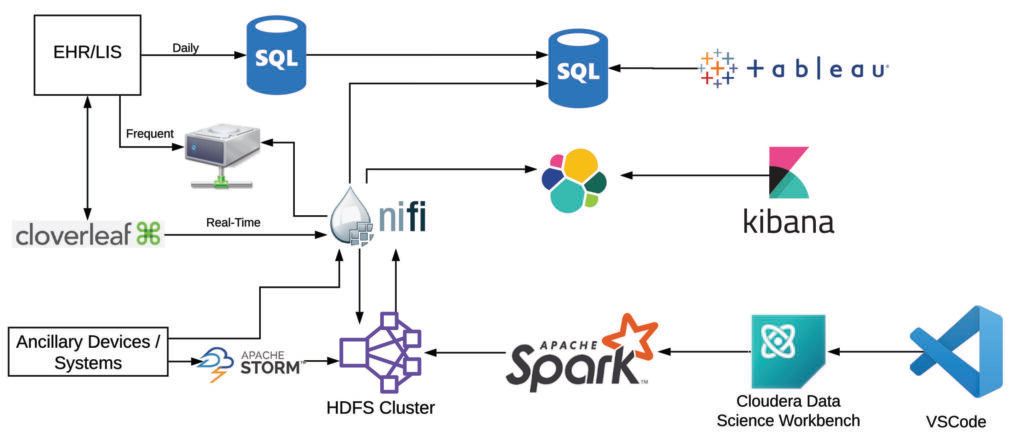
Because of the data volume and needs for integration, preprocessing is done at scale in mini-batches with Spark, with most jobs now executed via Cloudera Data Science Workbench (CDSW). This allows us to version control and follow standard development best practices for our preprocessing and analytic pipelines (code branching, unit testing, and merge requests), as well as the ability to use local integrated development environments (IDEs), primarily VSCode. Post-processing and post-analysis, data are transferred back to HDFS for storage and then loaded into downstream data management tools (SQL Server and elasticsearch) to support real-time visualization and reporting (with Tableau and Kibana).
While these complex data sets require several tools to create actionable insights, we tend to use repeatable architectures for each of our pipelines, and the tools are a small subset of the broad big data & AI landscape. Since we have developed out the organizational architecture to support a variety of downstream analytics, we are able to rapidly iterate and deliver the data necessary to support operational intelligence, clinical care delivery, and advance discovery in a rapidly evolving environment.